Ralph Wiggum Loops: The Downsides
Ralph Wiggum Loops: The Downsides
“I bent my Wookiee” - Ralph Wiggum
Yesterday I wrote about running autonomous AI coding agents overnight. 71 issues completed! 37 version bumps! Sounds great, right?
Let’s talk about the other side.
The Costs
API Usage
That 9-hour run with 3 agents ate 17% of my weekly Claude Code Pro tokens. In one day. Running this continuously would blow through the weekly allocation in about 2.5 days.
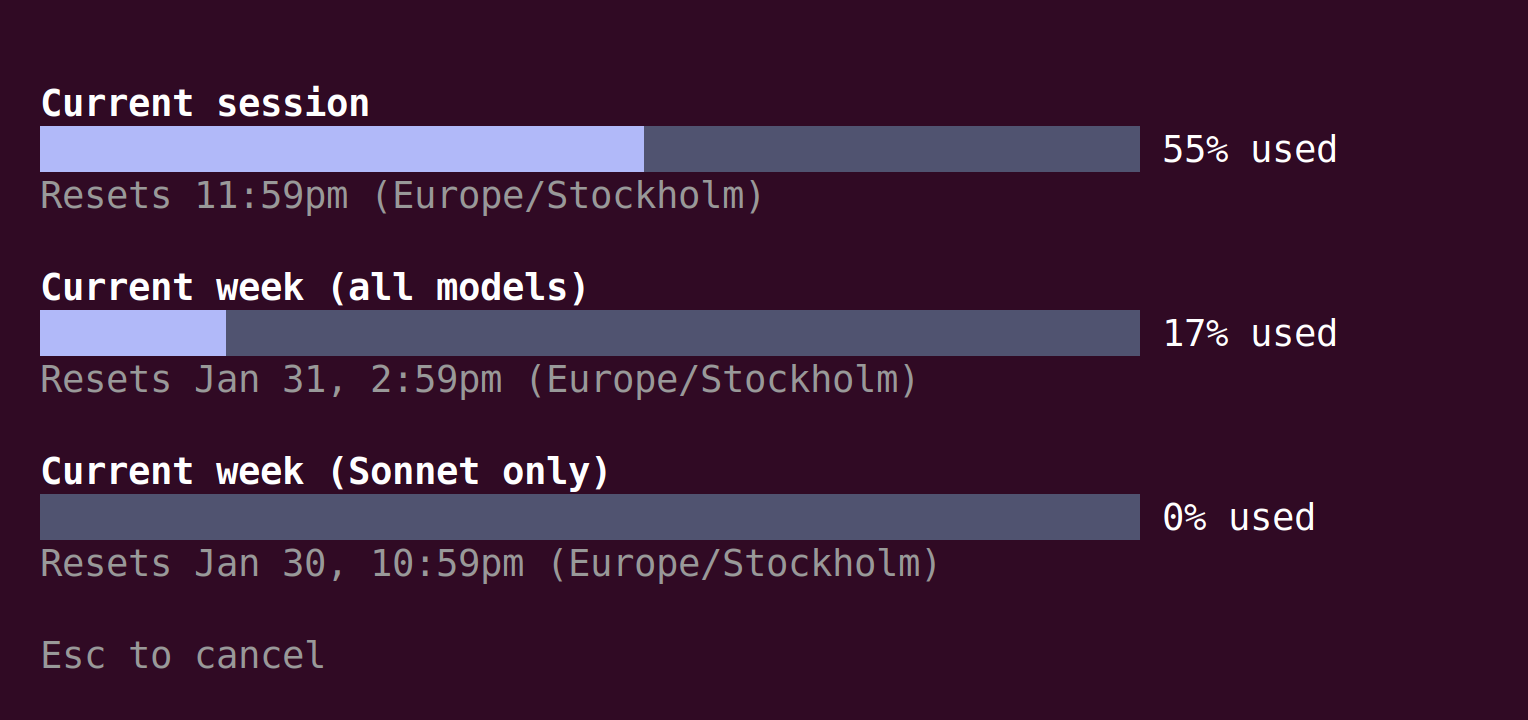
The math doesn’t math for sustained autonomous operation on a Pro subscription.
CI/CD Costs
Here’s my GitHub Actions metered usage for January:
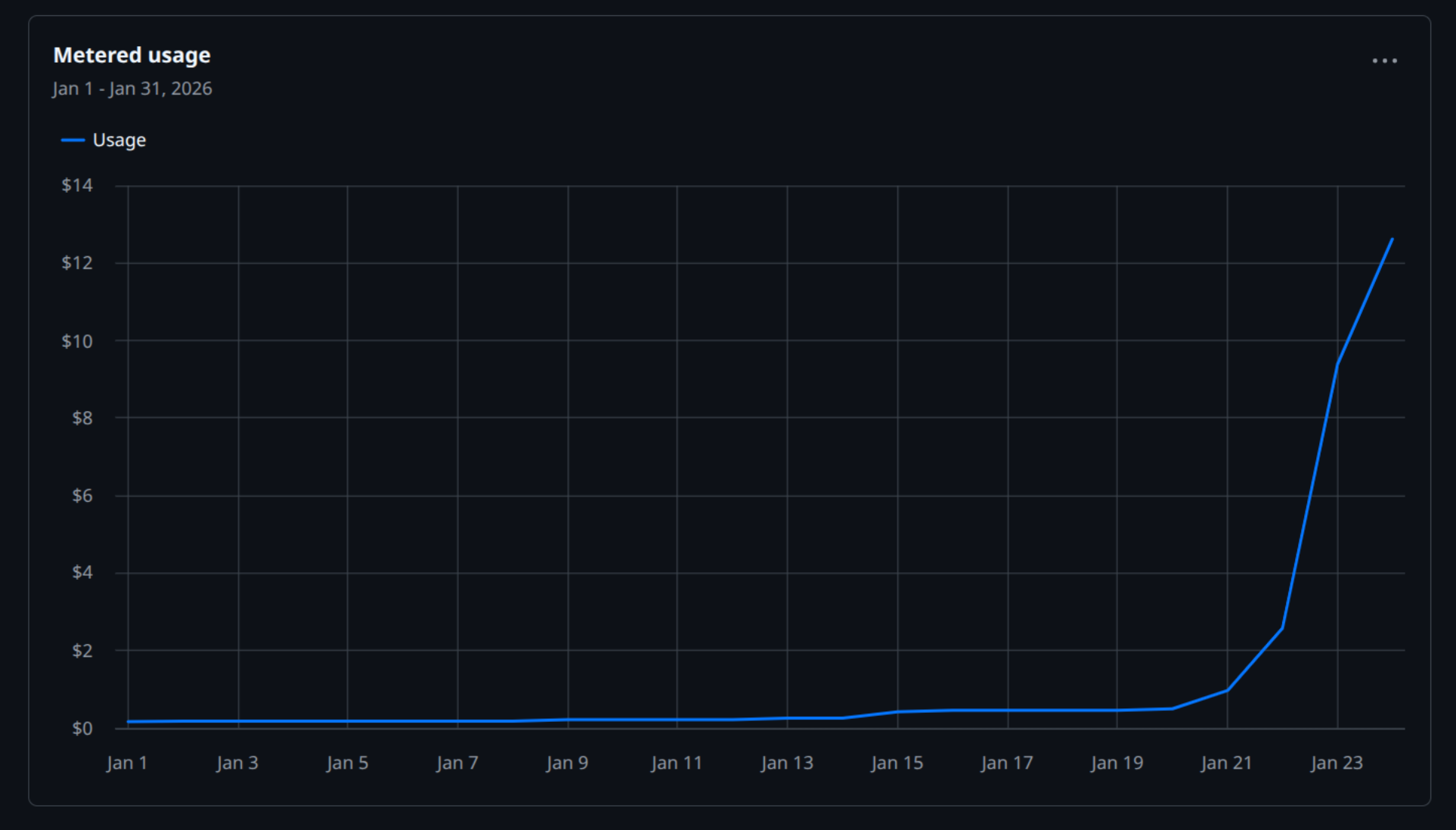
See that hockey stick? That’s 71 PRs worth of CI runs. Each PR triggers tests, builds, linting. Multiply by 3 agents churning through issues and you get a $12+ spike in a day or two.
Not catastrophic, but extrapolate to a full month of autonomous operation and you’re looking at real money. If your CI pipeline is heavier (integration tests, multiple environments, deployment previews), this gets expensive fast.
The Hidden Cost: Regressions
This one doesn’t show up in billing dashboards.
I had a cheat code feature. Type 1337h4xx0r, get dev mode. Simple. It worked. Then it didn’t. I created a fix issue, an agent fixed it. Then it broke again. Then it got fixed. Then it broke again.
Three times the same feature broke because agents don’t understand context. Each one optimized for “close this issue” without understanding they were touching shared code with implicit dependencies.
The cheat code kept breaking because:
- It parses user input
- Menu selection also parses user input
- They conflict on strings that start with numbers
- No agent knew about this conflict
- Each “fix” just reshuffled the bug
This is the fundamental problem: agents work on issues in isolation but codebases are interconnected systems.
The Coherence Problem
After 71 issues, I have 71 features that individually work (mostly) and collectively form… not quite a game. More like a game-shaped pile of features.
- Combat works
- Dialogue works
- Heat system works
- But do they work together?
- Does the game feel right?
No agent is asking those questions. They’re asking “do the tests pass?” and “can I close this issue?”
Unit tests verify individual components. Integration tests verify interfaces. But nothing verifies coherence - that the product makes sense as a whole.
What Actually Broke
Some specific failures from the run:
The parseInt Problem
JavaScript’s parseInt("1337h4xx0r") returns 1337. An agent “fixed” input handling by using parseInt, which silently broke the cheat code by treating it as menu selection. Tests passed because no test checked this edge case.
State Drift
Multiple agents touched the game state structure. Each made sensible local changes. The result was inconsistent state handling - some features expected gameStore.party, others used userStore.currentParty. Both “worked” in isolation.
Duplicate Implementations
Two agents independently decided the codebase needed a utility function. Both implemented it. Both merged (in different files). Now there are two slightly different implementations of the same thing.
Documentation Rot
Agents updated code but not always the docs referencing that code. The README still describes a flow that changed 20 issues ago.
The Fundamental Tension
Autonomous loops optimize for:
- Closing issues
- Passing tests
- Local correctness
Products need:
- Coherent user experience
- Features that work together
- Holistic quality
These goals don’t align automatically. You can have 100% of issues closed and 100% of tests passing while the product slowly becomes unusable.
Potential Mitigations
I’m exploring a Feature Registry - a living document that tracks all features, what files they touch, and how they conflict. Agents would consult it before making changes and update it after merging.
The theory: if an agent knows “this file is touched by the cheat code system and the menu selection system, and they conflict on input parsing,” it might not blindly break one while fixing the other.
Whether agents will actually use such a system reliably… that’s the experiment.
Other ideas:
- Golden path tests - End-to-end scenarios that verify the product works, not just the units
- Periodic human review - Accept that full autonomy doesn’t work yet, inject human judgment at intervals
- Scoped autonomy - Only let agents touch isolated, low-risk code; humans handle integration points
When It Works
To be fair, autonomous loops do work for certain tasks:
- Well-specified, isolated features with clear tests
- Bug fixes with obvious reproduction steps
- Refactoring with comprehensive test coverage
- Documentation and code cleanup
- Mechanical changes (add a field to 20 files)
The common thread: tasks where “tests pass” actually equals “done correctly.”
When It Doesn’t
- Features that need to integrate with existing systems
- Anything involving implicit dependencies
- User experience work
- Performance optimization
- “Make it feel right”
The common thread: tasks requiring judgment, context, or holistic thinking.
The Real Lesson
The 71 issues completed number is vanity metric. The real questions are:
- Is the product better?
- Do users (even just me) want to use it?
- Is the codebase healthier or just bigger?
I don’t have confident answers to those yet.
Autonomous coding agents are a powerful tool. But they’re a tool for throughput, not quality. They’ll build what you spec, quickly, in parallel. Whether what you spec is actually what you need - that’s still a human problem.
Or as Ralph would say: “The doctor said I wouldn’t have so many nose bleeds if I kept my finger outta there.”
Maybe I should keep my fingers in the loop a bit more.
The Numbers
For those keeping score:
| Metric | Value | Assessment |
|---|---|---|
| Issues completed | 71 | Impressive |
| Runtime | ~9 hours | Fast |
| API tokens consumed | 17% of weekly | Unsustainable |
| CI costs | ~$12 spike | Adds up |
| Regressions | Multiple | Problematic |
| Product coherence | Questionable | The real cost |
Would I do it again? Yes, but with more guardrails. The throughput is real. The quality control isn’t there yet.
Next post: Building a Feature Registry to teach agents about system coherence.
tags: